joelchan's working notes
Powered by 🌱Roam Garden@wangBiasNoveltyScience2017 for [[QUE - How might domain distance modulate the effects of analogies on creative output?]] | papers that make first-time difficulty-adjusted combinations of journals have higher (variance in) impact, mostly over long-run over short-run, frequently in lower-impact venues, and mostly in other fields
methods notes
sample: 661,643 papers published in 2001 from 251 subject categories, retrieved from Web of Science
 (p. 4)
(p. 4)
novelty = difficulty-adjusted first-time combination of journals
novelty per paper is sum over journal pairs binary novel/not multiplied by cosine distance between the co-citation vectors of the journal

difficulty is proxied by the cosine similarity between the co-citation vectors of the journals

filter out journals that don't really get citations (er.... whyyyyyy if more novel papers tend to get published in lower impact factor journals on average). pay close attention to Appendix III

in this sense, it could be related to far analogies, but perhaps more closely to conceptual combination
why might journals be a reasonable proxy for conceptual chunks? domains?
better than keywords? (maybe too granular?)
or subject areas? (maybe too coarse?)
some have used MeSH headings.

might depend on there being a reasonably complete and high-quality ontology or controlled vocabulary
@uzziAtypicalCombinationsScientific2013 makes the same move (journals as proxies of bodies of knowledge)
for analysis, novelty was binned into three categories (no novelty, >= 1 novel combination, but overall score < 99th percentile for subject category, >= 99th percentile for subject category) due to a highly skewed distribution

not sure about this; would like to see robustness checks with a different estimation strategy. but ok i guess.
properties of novelty score: as expected, highly skewed (~89% of papers do not make novel combinations, and ones that do only score modestly after difficulty adjustment)

 (p. 4)
(p. 4)
results robust to categorical conception of novelty, as well as filtering of sample (see 5.7)
results ➰ breadcrumbs
summary fig
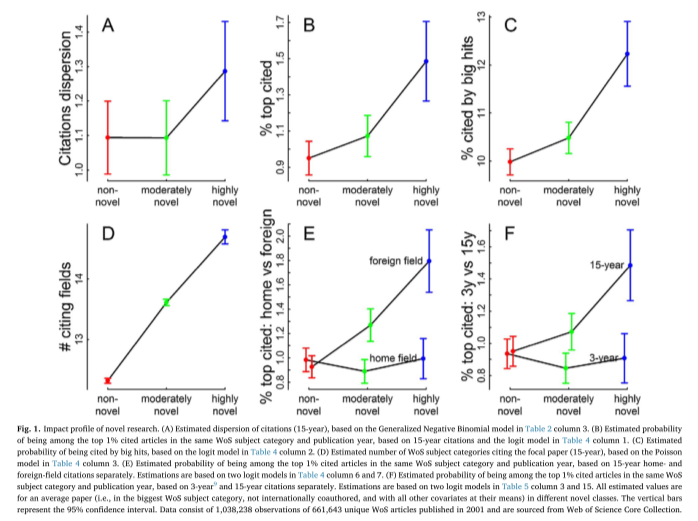
novelty strongly implies cross-disciplinary, but not the complement; [[EVD - highly novel combinations of cited journals in a paper were almost always cross-disciplinary, but cross-disciplinary combinations were infrequently novel - @wangBiasNoveltyScience2017]]
novelty --> higher variance in impact: [[EVD - highly novel papers had higher variance in their citation outcomes over a 15-year window, biased towards the higher impact tail of the distribution - @wangBiasNoveltyScience2017]]
5.1

GNB model Poisson regression
novelty --> big hit, esp. in long run, and outside home field: [[EVD - highly novel papers were more likely to be in the top 1% of citations in the long run, but not in the short run, and particularly in other fields - @wangBiasNoveltyScience2017]]
novelty --> lower impact factor journal, ceteris paribus: [[EVD - highly novel papers were more likely to be published in lower impact journals - @wangBiasNoveltyScience2017]]
 (p. 7)
(p. 7)
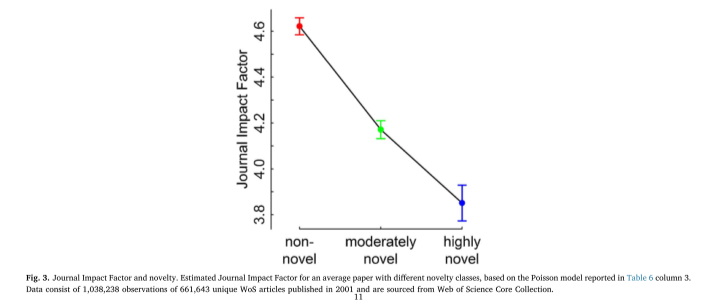 (p. 11)
(p. 11)
discussion
main claim here is that [[CLM - bibliometric measures are biased against novel breakthrough research - @wangBiasNoveltyScience2017]]
idea of "sleeping beauty" seems interesting, also as a keyword related to [[CLM - True creative breakthroughs often take a long time to develop]]

authors propose novel conceptual combinations (implicitly "inside a discipline"?? or outside??) as mechanisms for outsider innovation

would be really fun if we had the data to tease out differences between novel conceptual combinations that are close/far from the home/target discipline
if farther, then something new is being brought in (direct transfer)
if nearer, then maybe it's more about novel problem framing that allows for novel combination of existing pieces
for now, we know this connects well to far analogies because ~96% of the novel combinations are cross-disciplinary. which... makes sense based on how they define it.
the measurement of impact in terms of the long run outcomes for a single paper seem... off to me. i want to know about field-wide changes. which i suppose is not really possible to glean from citation data, because they involve counterfactuals. maybe in some limited cases we can get some natural experiments to compare.
i keep thinking about relationships between this and literature-based discovery! which has a similar intuition about basically "undiscovered public knowledge" (undiscovered fruitful connections between things)
the results on delayed recognition and lower-impact factor REALLY throw a wrench in heuristics that focus on filtering papers based on "top-tier venues"
yeah you can recover by buzz making its way through the community post-hoc, but based on the dynamics laid out here, basically guarantees that you'll be like... 7 years behind the curve on new breakthroughs? in exchange for what? higher short-run throughput maybe?
how far does this extend? to workshop papers? "just books" (no peer-reviewed journal papers???)
see, e.g., this book on Naturalistic Decision-Making
my intuition is also that this *underestimates* the delayed recognition penalty, when accounting for other forces like active prestige differentials and so on
and i really wonder if things have changed now: this was for papers published in 2001; this was pre-Google Scholar, pre-BERT, and pre-Twitter - and throughout this time, my feeling is that the constricting forces of publish or perish have only gotten stronger
should really pay attention to the variance in these effects: how tight is the relationship? we know for sure that the variance in hits
it's hard/impossible to tease apart variance due to extraneous factors vs. variance due to intrinsic variation in the quality of hte outcome
woudl really want to dive into the highly novel combos that didn't pan out, and see what was going on
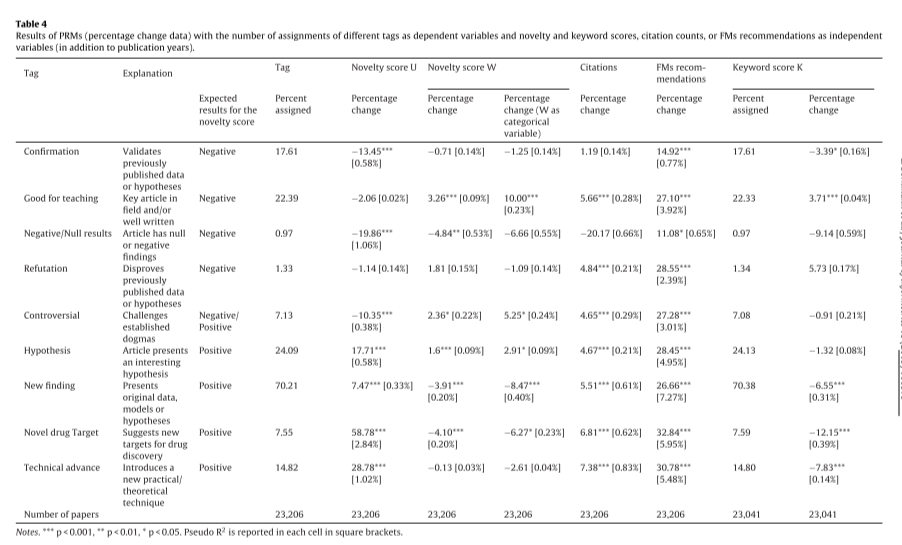
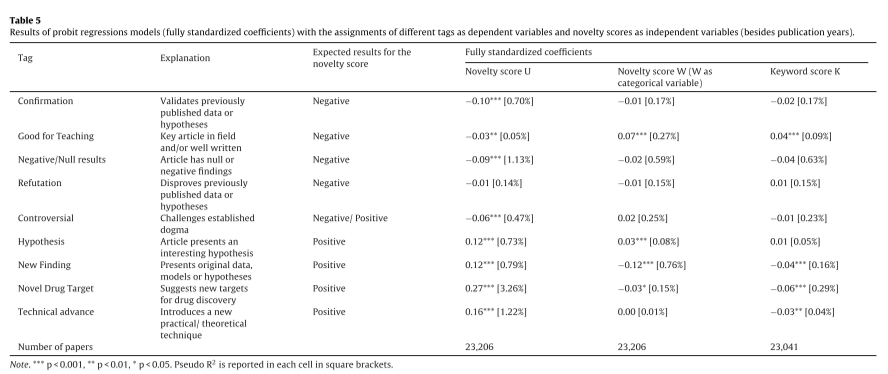
some questioning of the novelty measure in a later paper (@bornmannWeMeasureNovelty2019) comparing it to @uzziAtypicalCombinationsScientific2013's measure in terms of correlation to F1000 Prime ratings of biomed papers: depending on how you slice it, this is a plus or minus, since one key result in Wang is the asymmetry between home vs. foreign impact, and these F1000 tags are for papers that get recommended
tags for recommended papers

poisson
binary
basic result of [[EVD - highly novel papers were more likely to be in the top 1% of citations in the long run, but not in the short run, and particularly in other fields - @wangBiasNoveltyScience2017]] seems to be replicated by a later shorter paper focusing only on physicists: @mairesseNoveltyScienceImpact2018 - noting that this was a sample of papers from 2005-2009, so it starts to get a little bit at my misgivings about generalizing from a sample from 2001 (although it also pushes in the opposite direction by focusing only on physics)